* RAG(Retrieval-Augmented Generation) : 검색 기반 생성
ex) AI에게 회사 내부 데이터 정보를 요청하고 답변을 받고 싶을 때 AI는 해당 정보를 가지고 있지 않기 때문에
응답을 줄 수 없다.
이걸 가능하게 하기 위해 AI에게 회사 내부 데이터를 vector화 해서 전달하고, vector화해서 전달하기 위해 임베딩이란 것을 사용한다.
* pdf와 같은 파일들을 벡터화해서 벡터 DB에 저장해야한다.
1) manual Trigger 노드 추가
2) google Drive > Search files and folders - 구글 드라이브에서 목록을 다운로드 하기 위해 구글 드라이브 노드 연결 (Credential 생성 필요)
2-1) 구글 클라우드 콘솔 접속 > 왼쪽 상단 설정 > API 및 서비스 > 사용자 인증 정보
> OAuth 2.0 클라이언트 ID가 없어서 하나 생성해줬다!


클라이언트 ID를 복사해준 후 n8n의 Google Drive account에 Client ID에 붙여넣어준다.
그리고 Client Secret에 클라이언트 보안 비밀번호 값을 복사해서 입력해준다.

(인증하는데 한시간씀 ㅎ..)
- Return All을 체크해서 모든 목록을 다 받도록 설정
- Add Filter > Folder > From list > 어떤 폴더를 가져올지 골라야한다.

- Google Drive API도 사용하기로 설정되어 있어야 한다.
> Refresh List > 기존 SQLD 폴더에 이론 PDF 파일이 있길래 여기로 경로를 설정했다.

별로 없지만.. 리스트를 기져오는걸 확인할 수 있다 !
가져온 이 파일들을 다음 노드에서 다운로드를 해야한다. Google Drive > Download file을 클릭

오.. id 값을 File 쪽으로 끌어다놓으면 자동으로 인식한다! Execute step 클릭 시 파일 목록을 다운로드한다.
파일 목록을 다운로드 받으면 그 pdf를 텍스트 형태로 바꿔야한다.
Extract from File (From PDF)
다운로드 받은 바이너리 형태의 파일이 PDF에서 텍스트를 추출해주게 된다.
이 다음에는 벡터 DB에 저장해줘야 한다.

* 벡터 데이터베이스
- 글자들을 숫자로 바꿔준다. 숫자는 부동소수점으로 0.1233... 이런식
이렇게 글자를 숫자로 바꿔주는걸 임베딩이라고 한다.
이 글자를 단순히 숫자로 매칭하는 개념이 아니라 이 글자의 의미를 숫자화 시켜서 표현하는 방식을 임베딩이라고 한다.
이 작업을 할 때 임베딩 모델을 사용한다. Open AI, 라마..
소수점으로 이루어져 있는 값을 저장할 수 있는 공간을 벡터 DB라고 한다.
'글자의 의미'를 검색하는 것이 목적
- Qdrant Vector Store(Add documents to vector store) 노드를 추가해준다.
Qdrant Collection 영역에 어디다가 데이터를 입력해줄 것인지를 선택해줘야 하는데, 이걸 만들어줘야한다.

qdrant:
image: qdrant/qdrant:latest
container_name: my-qdrant
ports:
- "6333:6333"
- "6334:6334"
volumes:
- qdrant_data:/qdrant/storage
restart: unless-stopped
volumes:
n8n_data:
postgres_data:
n8n_files:
n8n_logs:
qdrant_data:
- 컬렉션을 만들기 위해 위 대시보드 화면에서 Quickstart 클릭

임베딩을 어떤 모델로 할건지가 vectors의 size를 결정한다.
distance가 Dot으로 되어있는데 어떤식의 알고리즘을 써서 유사도를 찾아내는지도 AI의 임베딩 모델에 따라 결정이 된다.
강좌는 Open AI의 text-embedding-3-large(3072차원) 모델을 사용하여 진행.
distance는 유사도를 어떤식으로 측정할것인지에 대한건데 Open AI가 추천하는건 "Cosine" 방식을 추천한다. (아니면 유클리드)

Run을 누르면 오른쪽처럼 나온다.
왼쪽에 있는 Collections 메뉴를 클릭하면

이렇게 방금 만든 Collection이 추가된 걸 볼 수 있다.

그리고 Qdrant Collection 부분에서 ...으로 되어있는 부분을 클릭해주고, Refresh List를 하면 방금 만든 Collection이 리스트에 표시되고 이걸 선택할 수 있다.
* OpenAI 계정 생성 및 키 발급
https://platform.openai.com/api-keys
계정 생성 > 결제 수단 등록 > 키 발급(안전한 곳에 꼭 키 잘 보관)

이 다음은 추가 노드 2개를 설정해줘야 한다.
임베딩 - Embeddings OpenAI

Document는 Default Data Loader로 어떤식으로 데이터를 읽어서 처리하는지 설정하는 것이다.
Recursive Character Text Splitter 추가

긴 내용이 있다면 text spliter로 3000글자를 자르고, 하나하나씩 벡터화해서 저장하는 방식으로 동작.
overlap은 3000글자씩 자를 때 500글자씩 겹치겠다는 의미.
의미가 끝 단위에 있는 경우 이상한 결과가 나올 수 있기 때문에 오버랩으로 더 의미 있는 결과를 추출할 수 있다.
recursive는 3000글자를 기준으로 하는게 아니라 문단으로 시도해서 안되면 문장으로 줄이고, 안되면 단어로 줄이는 식으로 자기 스스로가 최적의 의미를 유지하는 기준으로 계속 시도를 하게 된다.
(청크 사이즈와 overlap 사이즈는 정답이 없다)


새로고침하면 이렇게 1198개의 벡터 데이터가 저장된걸 확인할 수 있다.

클릭하면 이렇게 ..
* 활용
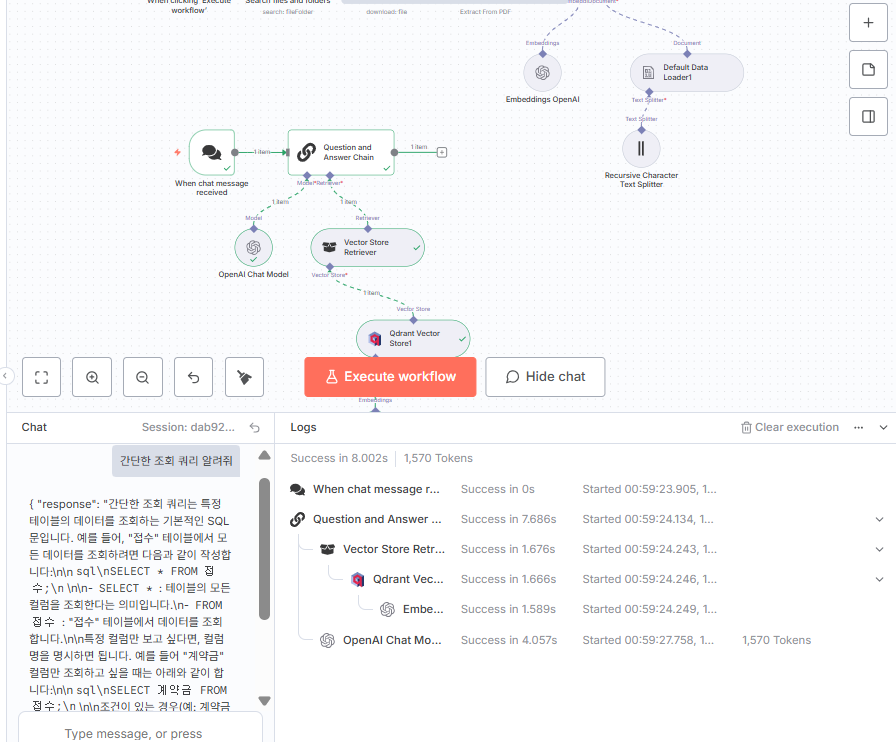
단순하게 채팅 노드를 활용해서 진행
Chat Trigger 노드 추가 > Question and Answer Chain (프롬프트는 채팅에 입력한 거 그대로 사용) > OpenAI Chat Model > Vector Store Retriever > Qdrant Vector Store1(sqld 연결)

이 상태에서 채팅을 열어서 입력할 것이고, 우리가 저장한 벡터 DB를 기준으로 얘가 대답해줄 것이다.
* 출처
'AI' 카테고리의 다른 글
| N8N으로 뉴스 요약 AI 만들기: 벡터 DB + 웹검색 통합 RAG 시스템 구현법 (0) | 2025.09.16 |
|---|---|
| Redis 설정하기 (0) | 2025.09.15 |
| n8n의 ngrok 설정하기 (0) | 2025.09.14 |
| n8n + MCP로 나만의 AI 카톡 비서 만들기 (2) | 2025.09.07 |
| n8n 카톡 메시지 전송 노드 만들기 (2) | 2025.09.04 |